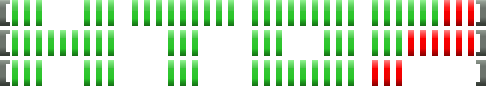
htop 完全指南:Linux 进程监控工具详解
从 CPU 负载、进程状态到内存管理,一文彻底搞懂 htop 的每一个指标和用法。
概述
htop 是 Linux 系统管理员最常用的进程监控工具之一。它比传统的 top 更直观,支持彩色显示、鼠标操作和交互式进程管理。但对于很多新手来说,htop 界面上的各项指标——CPU 颜色条、进程状态字母、VIRT/RES/SHR 内存列——常常令人困惑。
从零开始,逐一拆解 htop 中的每一个信息块,彻底理解 Linux 进程监控。
一、Uptime(运行时间)与 Load Average(负载均值)
在 htop 的左上角,你会看到系统运行时间(uptime)和负载均值(load average)。
运行时间
显示系统已运行了多久。你可以通过以下命令获取相同信息:
cat /proc/uptime输出两个数字:
- 第一个数字:系统启动后的总秒数
- 第二个数字:系统空闲的总秒数(多核系统上此值可能大于运行时间)
负载均值
负载均值有三个数字,分别代表过去 1 分钟、5 分钟和 15 分钟的平均负载。紧随其后的是当前正在运行的进程数 / 总进程数,以及最后一个使用的进程 ID(PID)。
什么是负载? 负载是通过统计处于 运行态(running) 和 不可中断睡眠态(uninterruptible sleep) 的进程数量得出的。它并不是 CPU 使用率的百分比,而是一个进程数量的绝对值。
严格来说,负载均值是指数衰减移动平均,而非简单的算术平均。1 分钟负载均值包含了约 63% 最近 1 分钟的活动和约 37% 更早的历史活动。
如何理解负载值?
- 单核 CPU 上负载为 1.0 = CPU 利用率 100%
- 双核 CPU 上负载为 1.0 = CPU 利用率 50%
- 若负载持续高于 CPU 核心数,说明进程在排队等待,系统可能出现延迟
为什么有时负载高但 CPU 利用率不高? 因为负载统计包含了不可中断睡眠进程(如等待 I/O 的进程),这些进程并不消耗 CPU 资源。例如 NFS 挂载卡住时,大量进程进入 D 状态,负载飙升但 CPU 却很空闲。
二、进程状态(Process States)
htop 中每个进程都有一个状态字母,通常显示在 STAT 列。以下是常见的进程状态:
R — 运行或可运行(Running / Runnable)
进程当前正在 CPU 上执行指令,或者正在运行队列中等待被调度执行。当你编译代码或执行计算密集型任务时,进程处于此状态。
S — 可中断睡眠(Interruptible Sleep)
进程正在等待某个事件或条件发生,比如等待网络数据、等待用户输入、调用 sleep() 等。这是最常见的状态,绝大多数空闲进程都在此状态。
当事件发生时,内核将其状态设回 R。
可以使用信号中断此状态的进程。例如:
sleep 60
# 在另一个终端:
kill -INT <PID>D — 不可中断睡眠(Uninterruptible Sleep)
进程正在等待 I/O 操作完成,且无法被信号唤醒或中断。此状态通常持续时间很短(毫秒级),但如果持久存在则预示着问题——例如 NFS 挂载不可达、内存不足导致的大量换页。
为什么 D 状态令人头疼?
因为 kill -9 也无法杀掉 D 状态进程——杀死进程需要发送信号,但 D 状态的进程根本不处理任何信号。
Z — 僵尸进程(Zombie / Defunct)
子进程已终止,但父进程尚未通过 wait() 系统调用来回收其退出状态码。此时子进程变成了僵尸。
- 僵尸进程不占用内存,仅占用一个进程 ID
- 短暂存在的僵尸进程完全正常
- 长期存在的僵尸进程表明父进程有 bug
解决办法:
- 请父进程回收僵尸(发送
SIGCHLD信号) - 或者直接杀掉父进程,僵尸会被 init 进程(PID 1)接管并清理
T — 作业控制信号停止(Stopped by Job Control Signal)
进程被作业控制信号暂停。例如:
- 在终端中按
Ctrl+Z - 发送
SIGSTOP信号
可以使用 fg(前台恢复)或 bg(后台恢复)重新运行,或发送 SIGCONT 信号。
t — 调试器跟踪停止(Stopped by Debugger)
进程正在被调试器(如 gdb)跟踪。当调试器 attach 到进程时,进程进入此状态。
三、CPU 使用率与颜色含义
htop 顶部有一排 CPU 核心指示条,每个条代表一个逻辑核心。颜色含义如下:
| 颜色 | 含义 |
|---|---|
| 蓝色 | 低优先级线程(nice > 0) |
| 绿色 | 普通优先级线程 |
| 红色 | 内核线程(系统调用) |
| 橙色/黄色 | 可中断(IRQ)时间 |
你也可以使用 mpstat -P ALL 1 查看更详细的瞬时 CPU 利用率:
PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
四、进程优先级与 Nice 值
Linux 是一个多任务操作系统,内核调度器负责决定哪个进程使用 CPU。你可以通过 Nice 值影响调度决策。
Nice 值(用户空间优先级)
范围:-20(最高优先级)到 19(最低优先级)
值越小,优先级越高。直觉上,"nice" 的进程会"让出"CPU 时间给其他进程。
每增加 1 个 Nice 值,大约让出 10% 的 CPU 时间。
设置 Nice 值:
# 启动时设置
nice -n 10 ./myprogram
# 运行时更改
renice 10 -p <PID>Priority(内核空间优先级)
范围:0 ~ 139
- 0 ~ 99:实时进程
- 100 ~ 139:用户进程
Nice 值(-2019)映射到 Priority(100139):Priority = 120 + Nice。
五、内存使用:VIRT / RES / SHR / MEM
进程的内存使用是 Linux 中最容易被误解的指标之一。每个进程拥有独立的虚拟地址空间,内核负责将虚拟地址映射到物理内存或磁盘。
VIRT(虚拟内存)
进程使用的全部虚拟内存总量。包括:
- 代码段、数据段
- 共享库
- 已换出的页面
- 已映射但未使用的页面
- 内存映射文件
如果一个应用申请了 1 GB 内存但只使用 1 MB,VIRT 仍显示 1 GB。大多数情况下,VIRT 不是有用的指标。
RES(驻留内存)
进程当前在物理内存中的非交换部分。这是比 VIRT 更好的内存使用指标。
但注意:
- 不包含已换出的内存
- 部分内存可能被其他进程共享(如共享库)
SHR(共享内存)
可能与其他进程共享的内存大小。这不意味着这部分内存被独占使用。
进程 VIRT RES SHR
/usr/bin/python 1.0G 15.5M 3.2M
MEM%(内存使用百分比)
进程当前使用的物理内存占系统总 RAM 的百分比。计算公式:RES / 总 RAM × 100%。
六、进程管理:信号(Signals)
htop 允许你通过 F9 或 k 键向进程发送信号。信号是进程间通信的一种方式。
常用信号
| 信号 | 编号 | 用途 |
|---|---|---|
| SIGINT | 2 | 中断进程(类似 Ctrl+C) |
| SIGTERM | 15 | 请求终止(进程可捕获后优雅退出) |
| SIGKILL | 9 | 强制杀死(进程无法捕获或忽略) |
| SIGSTOP | 19 | 暂停进程 |
| SIGCONT | 18 | 继续运行已暂停的进程 |
| SIGHUP | 1 | 挂起(通常用于重载配置) |
信号处理机制
SIGTERM(默认kill信号)→ 进程可以捕获并执行清理操作SIGKILL→ 内核直接终止,进程无响应机会- 你可以使用
kill -l查看所有信号列表
七、进程信息源:/proc 文件系统
htop 和 top 的所有信息都来自 /proc 伪文件系统。这是一个内核与用户空间交互的接口。
每个进程的信息位于 /proc/<PID>/ 目录下:
# 查看进程启动命令
cat /proc/<PID>/cmdline
# 查看进程环境变量
cat /proc/<PID>/environ
# 查看进程状态
cat /proc/<PID>/status
# 查看进程内存映射
cat /proc/<PID>/maps进程树结构
每个进程都有父进程(PPID),根是 PID 1 的 init/systemd 进程。
# 查看进程树
pstree -p
# 在 htop 中按 F5 进入树形视图当你在 shell 中运行命令时:
- Shell(如 bash)调用
fork()创建自身副本 - 子进程调用
exec()加载目标程序 - Shell 调用
wait()等待子进程结束
八、常见系统进程解读
htop 中常见的一些系统进程及其作用:
systemd-journald
收集和存储日志数据,使用结构化索引文件格式替代纯文本日志。可通过 journalctl 查询。
lvmetad
LVM 元数据缓存守护进程。如果你使用 LVM 逻辑卷管理,建议保留。
systemd-udevd
设备管理器,监听内核 uevent 事件并执行 udev 规则。
systemd-timesyncd
NTP 时间同步服务。
sshd
OpenSSH 守护进程,处理 SSH 远程连接。
cron / atd
- cron:周期性任务调度(常用)
- atd:一次性延时任务调度
rsyslogd
系统日志服务,填充 /var/log/ 目录下的日志文件。
agetty
终端管理进程,处理物理或虚拟终端(TTY)的登录。
accounts-daemon
账户服务,提供 D-Bus 接口查询和操作用户账户信息。
polkitd
授权框架(PolicyKit),提供比 sudo 更细粒度的权限控制。
九、文件描述符与重定向
理解文件描述符有助于你阅读 htop 中进程打开的文件信息。
标准流
| 文件描述符 | 名称 | 默认关联 |
|---|---|---|
| 0 | stdin | 键盘输入 |
| 1 | stdout | 终端输出 |
| 2 | stderr | 终端错误输出 |
重定向技巧
# 重定向 stderr 到 stdout
command 2>&1
# 或者(bash 4.0+)
command &> /dev/null
# 追加而不是覆盖
command >> file 2>&1记住:2>&1 中的 &1 不是文件名而是文件描述符 ID。如果写成 2>1,则会将 stderr 重定向到名为 1 的文件。
十、实用技巧与常见问题
1. 在 htop 中搜索进程
按 F3 输入进程名搜索。
2. 树形视图
按 F5 切换树形/列表视图,显示进程父子关系。
3. 过滤进程
按 F4 输入过滤条件,只显示匹配的进程。
4. 显示线程
按 H(大写)切换线程显示。
5. 显示内核线程
按 K(大写)切换内核线程显示。
6. 进程排序
按 F6 选择排序字段(CPU%、内存、PID 等)。
7. PuTTY 中显示异常
如果使用 PuTTY 连接时 htop 显示缺少元素,请检查终端类型设置(设为 xterm-256color 通常可解决)。
总结
htop 不仅仅是一个进程查看器,它是理解 Linux 系统运行状态的一扇窗口。读完后你应该能够:
- ✅ 读懂 CPU 负载均值的真实含义
- ✅ 区分 R/S/D/Z/T/t 六种进程状态
- ✅ 理解 VIRT/RES/SHR/MEM 内存指标
- ✅ 管理进程优先级和发送信号
- ✅ 利用
/proc文件系统深入排查问题
掌握这些知识后,下次遇到服务器响应慢、内存泄漏或进程卡死的问题时,你就能快速定位根因了。
© 2026 四月 · CC BY-NC-SA 4.0
原文链接:https://aprilzz.com/tools/htop-process-monitor-guide
相关文章
Deer-flow:字节跳动开源的长时程 AI Agent 框架
DeerFlow(Deep Exploration and Efficient Research Flow)是字节跳动开源的一款超级智能体编排框架,支持子智能体、长期记忆、沙箱执行和可扩展技能,可完成几乎任何复杂长时程任务。
ripgrep:比 grep 快 10 倍的命令行搜索工具
ripgrep (rg) 是一个用 Rust 编写的命令行搜索工具,比传统 grep 快 10 倍。本文深入分析其架构设计、正则引擎优化和 25 项基准测试,揭示它为何能同时实现极致性能和正确性。
JQ 入门:命令行 JSON 处理利器
JQ 是命令行处理 JSON 数据的瑞士军刀,本文从基础到进阶带你掌握这个必备工具。