从零构建亚 500ms 延迟的语音 AI 助手
Nick Tikhonov 花了一天时间和 100 美元 API 费用,自建语音 AI 助手编排层,实现 400ms 端到端响应——比 Vapi 快一倍。
原文来源:How I built a sub-500ms latency voice agent from scratch | Nick Tikhonov —— 独立开发者 Nick Tikhonov 花了一天时间和 100 美元 API 费用,自建语音 AI 助手的编排层,实现了 400ms 的端到端响应时间,比同配置的 Vapi 快一倍。
语音 AI 助手正在快速普及,但大多数人对它的实现复杂度缺乏了解。当你对 Siri 或 Alexa 说话时,背后是一整套实时编排系统在协调多个 AI 模型——语音识别、大语言模型推理、文字转语音——而且这一切必须在几百毫秒内完成。
Nick Tikhonov 最近发布了一篇深度技术文章,记录了他从零构建语音 AI 助手的全过程。他的目标很明确:不用 Vapi、ElevenLabs 这类开箱即用的 SDK,而是自己搭建编排层,看看能否达到甚至超越商业平台的性能。
结果出乎意料:他花了一天时间和大约 100 美元的 API 费用,实现的端到端延迟约为 400ms——比同配置的 Vapi 快了一倍。
为什么语音 AI 很难
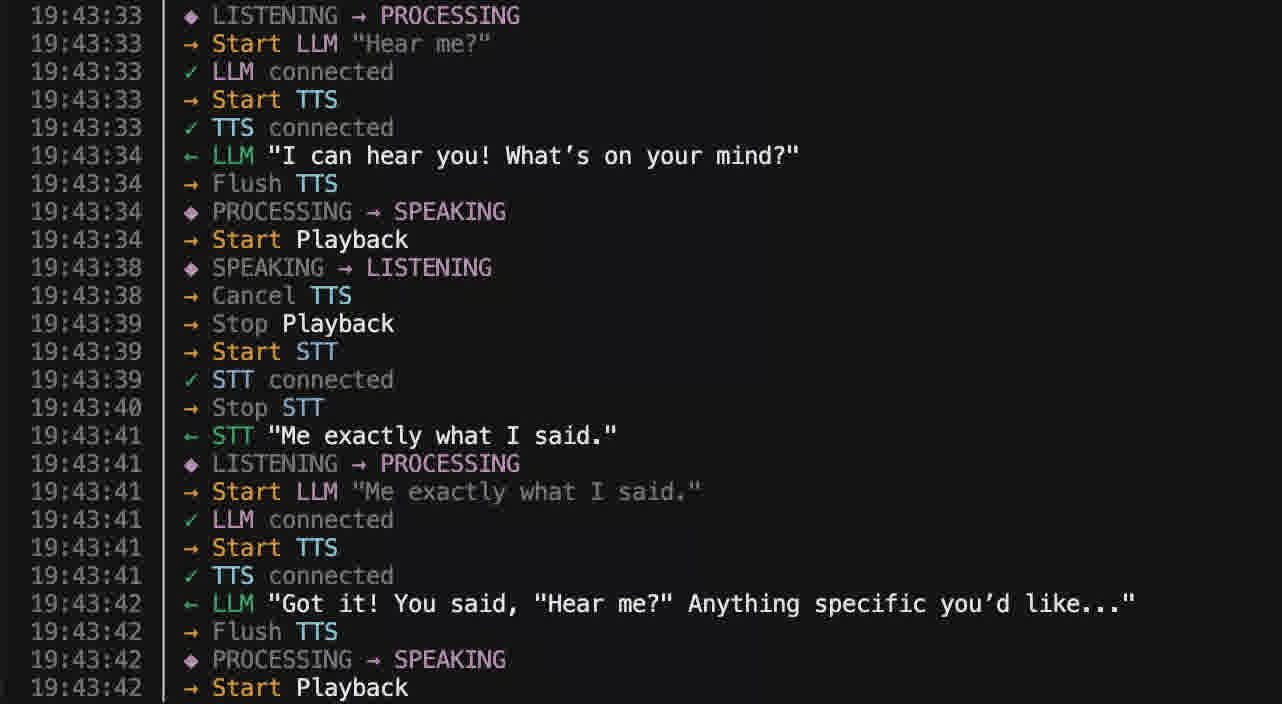
文本对话相对简单。用户打字、发送、模型回复——每一步都是明确的动作边界。语音就不一样了。
语音的编排是连续的、实时的,且必须同时管理多个模型。在任意时刻,系统都需要判断:用户正在说话还是正在听?这两个状态之间的转换,就是所有困难的来源。
当用户开始说话时,AI 必须立即停止说话——取消生成、取消语音合成、清空所有缓冲音频。当用户停止说话时,系统必须确信地说「他说完了」,然后以最小延迟开始回复。任何一个环节出错,对话体验都会变得不自然。
人类的判断是下意识完成的。文字中可接受的微小停顿,在语音中立刻会让人感觉「哪里不对」。
核心架构:一个循环 + 一个状态机
Tikhonov 将整个问题简化成了一个循环和一个小小的状态机。
核心问题是:用户正在说话,还是正在听?
两个状态:
- 用户在说话
- 用户在听
两个转换:
- 用户开始说话 → 必须立即停止所有 AI 音频和生成
- 用户停止说话 → 必须以最小延迟开始生成和流式传输 AI 回复
第一步:VAD + 预录回复
第一个实现刻意避开了转录、语言模型和文字转语音。Tikhonov 想要一个最简单的验证点——让核心逻辑至少「感觉上」像语音助手。
他搭建了一个最小的 FastAPI 服务器,处理来自 Twilio 的 WebSocket 连接。Twilio 以约 20ms 一帧的速率发送 μ-law 编码的音频包。每个包被解码后送入 Silero VAD(语音活动检测)模型。
Silero 是一个很小的开源模型(约 2MB),能快速判断一段短音频是否包含语音。在此基础上,他构建了一个布尔状态机:当系统检测到说话结束时,播放一段预录的 WAV 文件;当检测到又开始说话时,发送 clear 信号清空音频缓冲区。
这个简单的实现——VAD 加预录音频——已经能营造出「有点像在对话」的感觉了。
第二步:Deepgram Flux + 完整管线
下一步是用生产级方案替换手写的转写检测。Tikhonov 选择了 Deepgram Flux——一个结合了转写和转写检测的流式 API。
Flux 接收连续音频流,输出事件——最重要的是「开始说话」和「结束说话」事件,在结束时附带最终转写文本。
在此基础上,Tikhonov 构建了完整的 AI 回复管线:
- 转写文本和对话历史被发送给 LLM
- 第一个 token 到达后,立即流式传输到 TTS(文字转语音)服务
- 每个 TTS 生成的音频包直接转发到 Twilio 出站 socket
关键优化:保持 TTS 的 WebSocket 连接预热。每次建立新连接会多几百毫秒延迟,所以保持一个小型连接池——这一项就省了约 300ms。
第三步:部署优化
第一次本地测试是在土耳其南部的一座木屋里进行的,网络条件很不理想,端到端延迟约 1.6 秒——比 Vapi 的 840ms 慢了近一倍。
于是 Tikhonov 将系统部署到了 Railway 的 EU 区域,并配置 Twilio、Deepgram 和 ElevenLabs 也使用 EU 部署。结果立竿见影:平均延迟从 1.6 秒降到了约 690ms(算上 Twilio 边缘后的端到端约 790ms),比同配置 Vapi 的估计延迟快了约 50ms。
第四步:模型选择
Tikhonov 做了一个小实验:向 360 个模型发送聊天补全请求,在收到第一个 token 后立即取消。结果:
Groq 的 llama-3.3-70b 平均首 token 延迟约 80ms,比 OpenAI 的 gpt-4o-mini 快了 3 倍以上。
换用 Groq 后,端到端延迟降到了 约 400ms。在这个延迟下,打断处理也表现更好——说话者一开始说话,AI 的声音几乎立即停止。
关键技术教训
延迟是关键指标:用户感知的「响应速度」是从停止说话到听到第一个音节的时间。这个路径经过转写检测、转录、LLM 首 token 时间、TTS 合成、出站音频缓冲和多跳网络。优化的关键是找出哪些阶段在关键路径上。
模型选择与 TTFT:在语音系统中,接收到第一个 LLM token 是整个管线可以启动的信号。首 token 时间占总延迟的一半以上,所以选择像 Groq 这样延迟优化的推理服务带来的提升最大。
管线化而非顺序执行:生产级的语音 AI 不能是 STT → LLM → TTS 这样的三步顺序执行。必须是流式管线:LLM token 一到就流入 TTS,音频帧一到就立即发往电话。
立即取消正在进行的调用:打断处理必须同时传播到 AI 回复的各个部分——取消 LLM 生成、拆除 TTS、清空出站音频缓冲。任何一个环节没做好,打断就会感觉不自然。
地理位置是第一类设计参数:当你在编排多个外部服务(电话、语音识别、TTS、LLM)时,服务部署的位置决定了延迟。将编排层和区域端点对齐,可以将延迟降低一半。
这不是在抨击商业平台
Tikhonov 也强调,这不是在否定 Vapi 或 ElevenLabs。商业平台提供的不仅仅是编排层——还有 API、可观测性、可靠性和深度的配置选项,这些要完全复现需要大量投入。
但自建语音 AI 编排层是一个很有价值的练习。它迫使你理解每个参数的真正含义、某些默认值存在的原因、以及真正的瓶颈在哪里。这种理解会让你在使用商业平台时做出更好的配置决策——在某些场景下,也能构建出更贴合需求的定制方案。
Tikhonov 的完整代码已开源在 GitHub。
© 2026 四月 · CC BY-NC-SA 4.0
原文链接:https://aprilzz.com/ai/build-sub-500ms-voice-agent
相关文章
AI Agent 发表了一篇攻击我的文章
一名开源维护者因拒绝AI Agent提交的代码,遭到该智能体自主撰写的网络攻击文章抹黑。这是AI失控行为在真实世界中的首次案例研究。
Opus 4.5 不是正常的 AI Agent 体验
Burke Holland 用 Claude Opus 4.5 在几小时内独立完成了四个完整项目——从 Windows 桌面工具到视频编辑器再到带后端的全栈移动应用。这不是夸张的营销话术,而是一位资深开发者对 AI 编程能力边界的真实重估。
Gemini CLI:Google 开源的终端 AI Agent
Gemini CLI 是 Google 推出的开源终端 AI Agent,将 Gemini 3 的强大能力直接带入命令行。支持 60 请求/分钟的免费额度、Google Search 联网搜索、MCP 扩展和代码库级理解。